My data says that perf of malloc/free in actual programs (not fake ass shit calling malloc in a loop) is never affected by the call overhead. Not by dynamic call overhead, not even if you write a wrapper that uses a switch or indirect call to select mallocs. Reason is simple: malloc perf is all about data dependencies in the malloc/free path and how many cache misses it causes or prevents. Adding indirection on the malloc call path is handled gracefully by the CPU’s ability to ILP, and malloc is a perfect candidate since it’s bottlenecks will be cache misses inside the malloc/free paths.
This was the case a few years back when the fastest pools were implemented with recursive data structures (e.g. linked lists for the freelists in gperftools).
In the new tcmalloc (and, I think, hoard?) the fastest pools are essentially slabs with bump allocation, so the fastest (and by far, the most common) calls are a grand total of 15 or so instructions, without many cache misses (size class lookups tend to stay in the cache). Call overhead can be a substantial chunk of that.
First of all, let’s be clear: for a lot of algorithms adding call overhead around them is free because the cpu predicts the call, predicts the return, and uses register renaming to handle arguments and return.
But that’s not the whole story. Malloc perf is about what happens on free and what happens when the program accesses that memory that malloc gave it.
When you factor that all in, it doesn’t matter how many instructions the malloc has. It matters whether those instructions form a bad dependency chain, if they miss cache, whether the memory we return is in the “best” place, and how much work happens in free (using the same metrics - dependency chain length and misses, not total number of instructions or whether there’s a call).
> First of all, let’s be clear: for a lot of algorithms adding call overhead around them is free because the cpu predicts the call, predicts the return, and uses register renaming to handle arguments and return.
This is only thinking at the hardware layer. There are also effects at the software layer.
Function calls not known to LTO prevent all sorts of compiler optimizations as well. In addition, as Jeff says on this thread, not being able to inline free means you get no benefit from sized-delete, which is a substantial improvement on some workloads. (I'd cite the exact number, but I'm not sure Google ever released it.)
LTO I will grant you. I don't think you need to meaningfully inline the body of delete to get sized-delete to work effectively. You do want to statically link your sized operator delete body though, obviously. As of the last time I tried this, trying to inline the actual body was difficult to make effective, though.
Agree, I shouldn't have been loose wrt the distinction between inlining and LTO. I think I also ran that experiment with inlining sized-deletes and came to the same (surprising, to me) conclusion.
Let’s be clear: even without LTO, the compiler knows what malloc and free do at a semantic level.
I buy the sized delete win, I’ve seen that too, in some niche cases. But that’s a far cry from the claim that not inlining malloc is bananas. If that’s all you got then this sounds like a stunning retreat from the thesis of Jeff’s post. You’re just saying that you’ve got a free that benefits from size specialization, which has nothing to do with whether malloc got inlined.
> even without LTO, the compiler knows what malloc and free do at a semantic level.
int *a = ...;
int b = *a;
malloc(42);
b = *a;
printf(b);
If malloc is an opaque function, can the compiler nonetheless eliminate the second `b = *a` load as dead because it "knows what malloc does"? Certainly not, right?
The compiler knows the semantics of malloc. Malloc as it appear in the source code doesn't even need to map 1:1 to calls to the library function, the compiler can remove and coalesce calls at will.
"Profiling a warehouse-scale computer" (by S. Kanev, et. al.) showed several % of CPU usage allocating and deallocating memory. While a malloc and free does have some data dependencies, the indirect jump (by dynamically linking) is an avoidable cost on the critical path by statically linking.
Since Haswell indirect jumps have negligible additional cost. See, e.g., "Branch Prediction and the Performance of Interpreters - Don't Trust Folklore", https://hal.inria.fr/hal-01100647
Perhaps Spectre mitigations have changed things, but we're still talking about a fraction of a fraction. As others have said, the best way to improve malloc performance is to not use malloc. Second best would be avoid allocations in critical sections so the allocator doesn't trash your CPU's prediction buffers.
Runtimes often uses a lot of small malloc/free calls in quick succession. Since I worked with implementing a runtime at Google I've seen the function call overhead go up to 20% of the cost of it in real programs, since the actual memory needed was very small.
You might argue that we should have done that optimization on our own, but we are just a small team doing an inhouse thing so we don't have those kind of resources, so to us it helps a lot that the the default malloc is very optimized.
>> My data says that perf of malloc/free in actual programs (not fake ass shit calling malloc in a loop) is never affected by the call overhead.
I have thought the same for a long time until I ran some benchmarks on some of our 3D modeling code that uses Open CASCADE, and found out that in some cases allocation overhead was over 20% of total time spent in the CAD kernel...
pizlonator is saying that the overhead of the function call itself (the “call” instruction itself) doesn’t matter relative to the body of that function. The body of the function still matters a lot.
> My data says that perf of malloc/free in actual programs (not fake ass shit calling malloc in a loop) is never affected by the call overhead.
Your data is legitimate, but you've got to ask yourself, would Jeff specifically and Google more generally care so much about it if it were also true for their use-cases?
Just because someone isn’t incompetent doesn’t mean that we should assume they are right. Highly competent people are often wrong. Questioning things is good.
Not everyone does per thread arenas as a way of solving this problem. And I don’t think any solution to locking in malloc is a silver bullet. Some schemes work exceedingly well for specific use cases. So, there will always be folks in the malloc space who think theirs is better or theirs completely solves the problem because it is better and does solve the problem for their use case.
A bit unrelated, but if anyone is interested, I recently watched Andrei Alexandrescu's 2015 talk about a composable allocator design in C++ and it was really interesting. And Andrei's presentation style was fantastic, per usual.
Note that this talk is about a std::allocator-like type, potentially on top of one of malloc/jemalloc/etc.
> For C++ programs, replacing malloc and free at runtime is the worst choice. When the compiler can see the definition of new and delete at build time it can generate far better programs. When it can’t see them, it generates out-of-line function calls to malloc for every operator new, which is bananas.
I feel like whenever I've dealt with general-purpose memory allocation (as opposed to special-purpose like from a stack buffer without freeing) this kind of overhead has been dwarfed by the actual overhead of the allocation and pointless to worry about. Is this not the case in others' experience?
I also think that if it does matter, it could be a sign you're using new too much.
In other words, the style of "invoke new every time I need a new object" is not really what most people who care about performance do. There are higher level patterns than that, and often pluggable allocators, which could make the call out-of-line anyway, etc.
This. Before trying to make allocation faster, try to eliminate them first. A lot of code I've seen in higher-level languages, even (or especially?) most C++, seems completely oblivious to the amount of memory manipulation they're doing.
"The fastest way to do something is to not do it at all."
C++ hits the particularly nasty sweet spot of hiding boilerplate just enough that you have no idea what you're actually calling while also not having a sophisticated JIT that can do escape analysis and other tricks to optimize that kind of code.
It doesn't help that, often, the default response to not having a clear understanding of resource ownership in a code-base is to make a copy.
I also find that people struggle to internalize the costs of memory allocation. These days, the default allocators on modern systems are fairly well tuned for crap code, and the cost of any one particular allocation is a complicated function of all the allocations that came before it. They're different orders of magnitude in the badness scale, but any one allocation never looks so bad, just like any one memory load/store never looks so bad.
My experience is that C++ programs that try to be "Java" are the worst programs, from the performance standpoint, that can be written of all. And here I mean the "Java" practice that whatever object you have, it has to be made with "new." When one wants the really good performance in C++ that's the worst one can do. And my observation includes all implicit allocations due to the use of the "containers." Not to mention other effects that then get to be problem by the long-running programs.
That being said, in the targets I used the compiler was effectively never able to avoid calling actual malloc and free behind the new, and that matches your experience: malloc an free themselves were much bigger overhead than a few instructions that wrapped them to appear as "new."
It was however a few years ago the last time I analyzed something like that -- specifically for the code which has to be really fast I simply avoid having these wrapped "malloc" allocations in the hot paths, so I haven't had to investigate that specific aspect.
Not really, it's more trying to use constexpr better and measuring everything as well as inlining as much as you can. This leads to extra compile times which you can combat with precompiled headers. Overall C++ just wins out heavily. Not because C is worse, but because the C codebases I've looked at tend to not put code in headers.
C also has a lot of void* which prevent the compiler from doing optimizations it otherwise could. C lacks template programming, which means they will try to reuse the same containers for everything, again lowering performance. Typically some kind of list based on macros.
This 'new-all-the-things' style is called the Java style, but it is a bit unfair to Java, as that languages was designed, among other things, to make this style, which was prevalent in OO-heavy C++ programs from the '90s, usable.
It is still somewhat common in OO heavy GUI libraries and applications like Qt, although there the allocation performance is probably not the biggest bottleneck.
> it is a bit unfair to Java, as that languages was designed, among other things, to make this style, which was prevalent in OO-heavy C++ programs from the '90s, usable.
It could be completely fair, however, unless that language now allows an alternative paradigm, which it didn't the last time I've checked. If that changed since, I'd be really glad to read about it.
The old GUI frameworks I used (e.g. MFC) surely weren't that bad as you claim: they did depend on the allocations, but not dogmatically like those writing Java-inspired C++ code later or today. I remember:
They worked even in the very memory-constrained systems with some GUI elements having the number of elements that would never be able to perform what they did had they been all "new"-ed. An example: an editor having a huge number of lines, working on the computer in which the total RAM was e.g. 4 MB, which included the one needed fro the code of the OS.
The "trick" in these frameworks was to have "new" only for those GUI elements which exist in very limited number of instances. The rest was the no-"new" wrapping of the calls to the low-level code, which was C or even assembly at that time.
I am plenty sure they did, as I started using C++ for GUI code around 1992, 4 years before Java was born.
As for the MFC, not only do CString, CArray, CDocumentView and everything CSomething depend on the heap, all the COM related classes only exist on the heap.
Nowadays even more so, given the role that COM has taken as main way for all new APIs after Vista, by building the Longhorn ideas with COM instead of .NET.
Even if it looks stack allocated, it is actually an handle to a COM/UWP instance.
> CArray ... everything CSomething depend on the heap
One can have only one allocation per CArray and when using MFC one doesn't have to keep everything in MFC CStrings at all. Specifically, I've used CSomething structures with pointers to the C-style strings which were part of the single allocated pool, for example. The MFC is carefully made to allow for many such use cases, which were, as I've said, actually fundamentally necessary to allow programming efficient applications under the older memory limitations and the older processor speeds.
Specifically, MFC allowed one to use MFC classes for things like CDocumentView, but to have the "work" part of the application conveniently NOT dependent on these, and to pass to the underlying Windows Win32 C-level interfaces everything as cleanly as assembly or C would allow.
I've used that and most performant applications used something similar.
> considering the programming language landscape at the time, if we leave C++ aside, it would be more correct to say Smalltalk
I'm quite sure Smalltalk didn't have a "new" mapped to malloc, and also most of other stuff that C++ had the way it had. Nevertheless, Smalltalk was also never something performant, it was more "an experiment" not an environment for many commercial products.
Regarding the "landscape" you are right that there were some people that influenced the "dogma" of "how C++ should be written" that actually didn't even know C++ or the consequences of their promotion of some "OOP techniques." Horrible stuff, if you asked me, was good only for the clueless managers and buzzword catchers, but never resulted in efficient applications, where the policy was to "do as the promoters say."
There are a wide variety of outcomes available when the implementation of global operator new is visible to the compiler. It may inline the entire new, and having done so it may also apply any other optimization that would apply to any other function. Without an allocator at build time the only thing it can do it generate a call to malloc. Leaving malloc resolution to runtime also negates all benefits of sized delete.
Have you ever seen operator new inlined in pratice? I've always seen it make a call to malloc, because I can't think of a compiler actually containing the implementation of a memory allocator inside of it…
I'm completely aware of everything you said, but it's not what I asked. I was very specifically not asking what is theoretically possible but what actually happens in practice. Because I don't see any evidence that this is actually the case in practice. For a memory allocator that has a legitimate general-purpose deallocator (i.e. ones that are reasonable replacements for malloc/free), my experience says this kind of overhead being worth optimizing is very much hypothetical rather than the reality. Of course for allocators that skip half the steps (e.g. don't bother to return memory dynamically or only work in specific cases) then the story might be very different but it's not really fair to compare them against general purpose ones?
Now I'm perfectly happy to accept my imagination/experience is just lacking and that's why I don't see such use cases, but I'm seeing multiple other top comments voicing the same concerns as I am, so I'm mostly suggesting a plausible example to demonstrate this is likely to really help convince people this might be the right thing to focus on.
My understanding is that compilers are allowed to treat malloc specially, i.e. they can assume that it returns non-aliasing memory, does not mutate other memory and can be elided if its result is unused.
I'm not aware of that being a blanket assumption they can make, is it? (Is it in the C++ standard?) That kind of thing is generally dictated by compiler-specific annotations (noalias etc.) which you can put on any function, and which shouldn't apply unless you write them explicitly...
on gcc you can use __attribute__((malloc)) to tell the compiler that your function is malloc-like (i.e. its result type won't alias any other pointer), but any call to the litterall 'malloc' function itself is implicitly treated as such even if you do not include the appropriate header and declare it yourself (you can use -fno-builtin-functions or -free-standing or something like that to disable this treatment).
Modern allocators are extremely optimized for a fast path which consists of tens of instructions and usually takes a few nanoseconds. Function call overheads are not negligible for this case.
Not an expert but I don't agree. You're talking about bump allocators I assume, a nursery area. Do much of that and the TLB gets used more, which can get expensive.
If it's not bump-allocating then you have to traverse data structures to find a suitable block of free mem. At the other end, each alloc() must get a free() and reclaiming and unifying memory to prevent fragmentation isn't cheap I guess.
It feels a little bit like saying modern cars are extremely optimized for a fast acceleration which consists of a 0-to-60 of 3 seconds instead of 9 seconds, and acceleration delay is not negligible in this case. I mean, I suppose you're right and it would be a 3x improvement, but surely you're not using your (general-purpose) heavyweight tool (car) to just zoom down the block and back at peak acceleration all the time, right? And if you really do have a niche requirement like that, aren't there bigger fish to fry here (like eliminating the car or the need to transport people there & back altogether)?
I'm saying it's very likely you should be looking into alternative approaches if the fast path performance is genuinely your bottleneck, and that in my experience it's overwhelmingly likely that that's not the case. Most likely you're doing too many dynamic memory allocations to begin with. Note that even if you invoke the fast path 20x more often than the slow path, it's still going to be peanuts if your slow path is 1000x slower.
Best way to support your point would be to illustrate with realistic examples instead of hypotheticals. Otherwise this is like the JIT vs. AOT debate that always goes nowhere because the JIT side only ever uses hypotheticals to support their case.
That's not fair, though, because it really depends on how often the fast path gets hit. In good dynamic language runtimes, for example, the fast path is extremely optimized and hit very often, so even though the slow path can be thousands or millions of times slower the application performance might track the fast path rather than the slow one.
Are you talking about implementing a dynamic language in C++? Sure, do whatever you want in that case. Seems pretty fair to >99.9(9...?)% of developers aren't doing that.
I think it's safe to say dynamic language writing is to dynamic memory allocation as NASCAR is to car acceleration. You (should) already know your metrics will necessarily differ from most other people's.
That was just an example of a place where fast path performance defined the runtime performance, as that’s how they become optimized. You can see a similar pattern when inserting keys into a hashmap, for example.
That only applies to short lived allocations in a garbage collected heap or allocation arenas that were specifically chosen on a case by case basis. Most memory allocations on the heap don't even happen in C or C++. Short lived objects exist on the stack and swapping your allocator with a different one won't change that.
That most allocations happen on the stack doesn't change the fact that most malloc implementations are still heavily optimized for the fast path. As far as I can tell the glibc implementation at least has a fast path for small allocations.
Yeah I think it's very situational. Like an arena allocator is going to give you a tremendous bump in allocation performance since you just allocate once and replace memory every frame - to give the gaming industry example.
I think it’s the other way around. Instead of redefining operator new() to allocate from an arena, user allocates memory from the arena and then constructs instance there using placement new.
> For C++ programs, replacing malloc and free at runtime is the worst choice. When the compiler can see the definition of new and delete at build time it can generate far better programs. When it can’t see them, it generates out-of-line function calls to malloc for every operator new, which is bananas.
This argument smells like bullshit, sorry, and it's totally not justified in the article. Giving just numbers without even explaining a potential causality points to benchmark setup failure more than anything.
Unless you are talking about statically linking your malloc implementation, your entire STL and all depending libraries AND then performing LTO on it, and even then I'd be surprised if there's any noticeable improvement over this.
Not to mention I don't know of _any_ real-life executable that does this...
There indeed isn't a ton of detail in TFA, and so I can understand your skepticism.
Jeff Baker is an expert on this at Google.
Until you've seen the sorts of analyses that are conducted inside of Google, it may be hard to appreciate the level of scrutiny that every CPU instruction in tcmalloc has gotten from people like Jeff.
> This argument smells like bullshit, sorry, and it's totally not justified in the article. Giving just numbers without even explaining a potential causality points to benchmark setup failure more than anything.
Why? This argument sounds perfectly reasonable and is true in many other contexts as well.
Can you compare `tcmalloc` to e.g. tcmalloc dynamically loaded, or jemalloc specified with Bazel's malloc option? It is unclear from the post whether the wins are improvements from the internal Google improvements to tcmalloc post-gperftools, or to reduction in overhead from bypassing the PLT
The big problem with malloc/new/free/delete is that the interface is way too flexible. Allowing objects to be allocated one thread and freed on another fundamentally requires a bunch of complicated bookkeeping. Particularly in C++ it's usually more productive to change your allocation strategy entirely if malloc/free is really a hot spot in your code.
Eh, on the fast path many allocators will just pull the block from what’s essentially a bump allocator on the allocating thread and then stick the block in the freeing thread’s tcache when it’s done with it, doing rebalancing once in a while when necessary. It’s not too horrible.
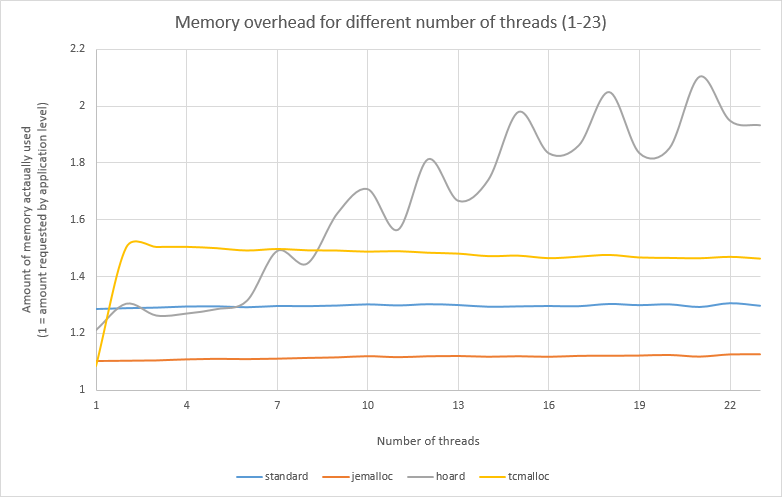
Note that there are other considerations like absolute allocation speed, like memory fragmentation, which isn't affected by inlining. In the ithare post they link, jemalloc thrashes all other allocators[1] on that front. It would be interesting to see if the newer version of tcmalloc is improved at all in that respect.
In this test jemalloc actually uses the most memory of all. With default tunings it uses 700k pages at peak, compared to 170k for tcmalloc and 131k for glibc. I have no idea if that is relevant in real life and I have never cared, so I didn't mention it.
That's due to differences in your workload - in e.g. Ruby on Rails, the total uncertainty of which objects are going to survive a request means that jemalloc does a much better job at packing.
That's actually quite interesting, as IIRC jemalloc has much looser alignment than other allocators and thus can give "tighter" blocks for small allocations.
Something that could help a lot with performance would be functions to handle memory for many small blocks at once.
Like a malloc extension function that allocates many small blocks at once. Rather than returning one block of size n, it would return k blocks of size n.
Of course the user could do something similar by allocating one big block of size k · n ordinarly. But then the user needs to keep track which small blocks belong to which big block, and it might too big, when some small blocks are not needed anymore. Say, the function needs k small blocks temporarily for processing, but only returns k/10 small blocks. Then 90% of the memory would be wasted.
But if you could allocate k small blocks at once, the allocator could allocate one big array of k·(n + sizeof metadata). Then each of the small blocks could be freed like a normally allocated block of size k, but they have all the advantages of quick allocation and cache locality like a big array.
Or, alternatively, there could be a partial free that does not free the entire malloced block, but only a part of it. Then you could allocate a block of size k·n, and when you do not need it anymore, free the 90% of the block that you do not need, but keep the 10% that you need.
Object pools are a pretty common pattern for that kind of usage. Is this any different, or are you just asking to push the "allocation" into the memory allocator instead?
The difference would be that each object can be freed individually when it is no longer needed.
Especially when the code that creates the objects and the code that uses/discards the objects are in two different projects.
Like a library that can load a JSON file as some kind of tree structure. Then someone uses the library, loads a file of a million objects, but then only needs a single object. All the other objects should be freed, but if they are in a pool, they cannot. The library does not know which object the user wants, and an user of the library should not need to know how the library allocates the objects
I'm not sure I understand the distinction. Why couldn't the parser maintaining that pool? If the two different projects (which I assume translates into two different object files or DLL's) belong in the same process, it's pretty straightforward for the parser to keep a singleton pool somewhere. If the two projects are in different processes, then it's probably better in terms of security to disallow sharing of that memory - and virtual memory spaces should abstract the space efficiency issues well enough for those purposes.
The problem is that the pool becomes too big and wastes memory
It is fine when the user keeps opening files and the parser can reuse the objects.
But eventually, the user has opened all the files he needs. Then the process will never open another file again, and none of the objects can be reused. But they also cannot be freed, when some objects are still used, e.g. when the user did not close all files.
Picking the best allocator was not my goal. I was writing about how to correctly use any allocator. I agree that mimalloc is worth evaluating. Note that Microsoft says this in their docs, which agrees with what I am driving at:
"""
For best performance in C++ programs, it is also recommended to override the global new and delete operators. For convience, mimalloc provides mimalloc-new-delete.h which does this for you -- just include it in a single(!) source file in your project.
"""
Not optimize them away entirely, but eliminate the actual function call through inlining. User-code can implement their own new and delete. If those implementations are available during compilation, then they are candidates for inlining just like any other function.
In my experience an applications specific pool works the best. Lets say a part of your programs does a bunch of malloc()s then frees... put it into a pool then delete the pool when its done.
When I backtrace from my malloc wrapper, injected with LD_PRELOAD, I see malloc, std::new, then the call site that involved new. Unless std::new is doing some funky shit (Like detecting dlsym("malloc") isn't glibc's malloc, and changing implementations) I have my doubts about the claim that dynamic replacement is costly. It appears new is already dynamically linking malloc.
That is the entire point of the post. If you leave the resolution of malloc to run time, the best you can hope for is that new calls malloc, out of line. If you build with an implementation of new, the outcomes may be dramatically better.
By the way there is no such thing as std::new. We are discussing ::new.
Heh, std::new was some cruft I got out of backtrace(3) with some wacky embedded tool chain.
Are these gains supposed to be from inlining the top level function of malloc into new? Compared to the costs of what can go on inside malloc... Is that the biggest problem?
Let’s not forget a benchmark is not a typical application. Just because it does improve without using dynamic linking does not conclude it would so in every application.
But, I definitely would not dynamically link a custom allocator. For me it would be the improved memory usage and performance, which I do not want to risk loosing.
The C++ allocator interface really needs to support realloc. Vector, in many cases, could avoid copying elements, particularly in cases where the move constructor is trivial --- e.g., vector<int>.
The post has no date, does not mention versions used or allocator tunables. Considering that this is a shifting landscape that makes it difficult to judge how relevant those results are today.
{kind=link}